Dictionaries and Sets in Python
Everything you have to know to safely Implement Dictionaries and Sets in Python.


So far we have talked about sequences and how powerful they can be if leveraged the right way, the Pythonic way! Now we are going to tackle dictionaries as they are considered a keystone of Python and every programming language.
Python standard library offers us handy and ready to use specialized mappings that other languages do not which make them even more useful.
We are going to start with one of the oldest and best features of dictionaries and that is Dict comprehensions.
Dict Comprehension
The syntax of list comprehension has been adapted to dictionaries, a DictComp builds a dict instance by taking the pairs {key:value} from any Iterable.
dial_codes = [
(880, 'Bangladesh'),
(55, 'Brazil'),
(86, 'China'),
(91, 'India'),
(62, 'Indonesia'),
(81, 'Japan'),
(234, 'Nigeria'),
(92, 'Pakistan'),
(7, 'Russia'),
(1, 'United States'),
]
country_dial = {country: code for code, country in dial_codes}
print(country_dial)
# {'Bangladesh': 880, 'Brazil': 55, 'China': 86, 'India': 91, 'Indonesia': 62, 'Japan': 81, 'Nigeria': 234, 'Pakistan': 92, 'Russia': 7, 'United States': 1}
code_less_than_70 = {code: country.upper() for country, code in sorted(country_dial.items()) if code < 70}
print(code_less_than_70)
# {55: 'BRAZIL', 62: 'INDONESIA', 7: 'RUSSIA', 1: 'UNITED STATES'}Unpacking mappings
Unpacking dictionaries is similar to unpacking a list only you will be unpacking a pair of {key:value} and it’s done with ** rather than *
There are two key points to retain:
- We can apply ** to more than one argument in a function call when keys are strings and unique. Duplicate keyword arguments are forbidden in function calls.
- ** can be used inside a dict literal also multiple times.
Example:
def dump(**kwargs):
return kwargs
print(dump(**{'x': 1}, y=2, **{'z': 3}))
# {'x': 1, 'y': 2, 'z': 3}
print({'a': 0, **{'x': 1}, 'y': 2, **{'z': 3, 'x': 4}}
# here duplicate keys are allowed and they get overwritten by the last occurence
#{'a': 0, 'x': 4, 'y': 2, 'z': 3}How to Merge Dictionaries?
This is another awesome feature that was added in 3.9 for dictionaries, that’s the support for | and |=, these are Sets union operators, the first creates a new mapping while the latter updates the first operand.
Example:
d1 = {'a': 1, 'b': 3}
d2 = {'a': 2, 'b': 4, 'c': 6}
print(d1 | d2)
# overwriting the last occurence
# {'a': 2, 'b': 4, 'c': 6}
d1 |= d2
print(d1)
# {'a': 2, 'b': 4, 'c': 6}Standard API of Mapping types
The collections.abc module provides the Mapping and MutableMapping ABCs(Abstract Basic Classes) describing the interfaces of dict and similar types, its goal is to formulize the standard interface.
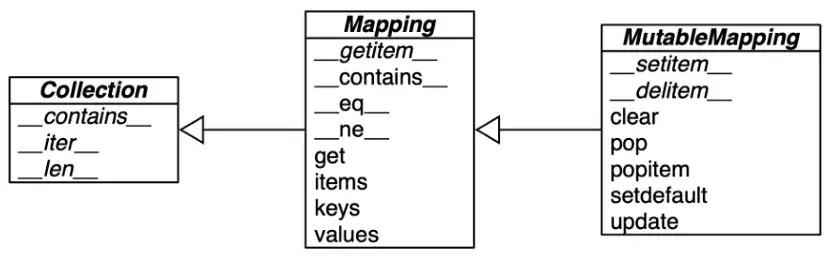
These ABCs are not to be implemented by developers, it’s better to extend UserDict or to wrap a dict instance by composition. All concrete mapping classes implement the ABCs and it’s better to extend them directly.
One last thing to mention, all mappings share the same limitation, keys must be hashable, ie. the keys never change during their lifetime.
For more details about the basic API for mappings here’s the official documentation link that gets into more details for every method.
Automatic Handling of Missing Keys
Imagine a scenario where a program tries to access a value in a dict by its key, only to not find the key. There are two ways to handle this:
- Use a defaultdict instead of a plain dict: a defaultdict instance creates items with a default value on demand whenever a missing key is searched using d[k] syntax.
from collections import defaultdict
# Function to return a default values for keys that is not present
def def_value():
return "This guest did not check in yet"
# Defining the dict
d = defaultdict(def_value)
d["guest_1"] = "Adam"
d["guest_2"] = "Eve"
print(d["guest_1"]) # Adam
print(d["guest_2"]) # Eve
print(d["guest_3"]) # This guest did not check in yet- Implement the __missing__ method in dict or any other mapping type.
class GuestDict(dict):
def __missing__(self, key):
return 'This guest did not check in yet'
x = {"guest_1": "Adam", "guest_2": "Eve"}
guest_dict = GuestDict(x)
# Try accessing missing key:
print(guest_dict['guest_3'])
# This guest did not check in yetVariations of dict
There are different variations of dict that are ready to use and we can leverage to gain time.
- collections.OrderedDict: regular dictionaries but have some extra capabilities relating to ordering operations. They have become less important now that the built-in dict class gained the ability to remember insertion order.
- collections.ChainMap: A ChainMap instance holds a list of mappings that can be searched as one. The lookup is performed on each input mapping in the order it appears in the constructor call, and succeeds as soon as the key is found in one of those mappings.
baseline = {'music': 'bach', 'art': 'rembrandt'}
adjustments = {'art': 'van gogh', 'opera': 'carmen'}
print(list(ChainMap(adjustments, baseline)))
# ['music', 'art', 'opera']- collections.Counter: A mapping that holds an integer count for each key. Updating an existing key adds to its count.
ct = collections.Counter('abracadabra')
print(ct)
# Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
ct.update('aaaaazzz')
print(ct)
# Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
print(ct.most_common(3))
# [('a', 10), ('z', 3), ('b', 2)]- shelve.Shelf: The shelve module(Pickle jars are stored on shelves) in the standard library provides persistent storage for a mapping of string keys to Python objects serialized in the Pickle binary format.
- UserDict: We mentioned before that it’s better to create a new mapping type by extending collections.UserDict rather than dict. The UserDict has some methods that are ready to use rather than having to implement or reinvent the wheel with extending the dict class.
- MappingProxyType: this is a wrapper class that given a mapping type returns a mappingproxy instance that is read only but mirrors the changes from the original mapping.
from types import MappingProxyType
d = {1: 'A'}
d_proxy = MappingProxyType(d)
print(d_proxy)
# mappingproxy({1: 'A'})
print(d_proxy[1])
# "A"
d[2] = 'B'
print(d_proxy)
# mappingproxy({1: 'A', 2: 'B'})
print(d_proxy[2])
# "B"Dictionary Views
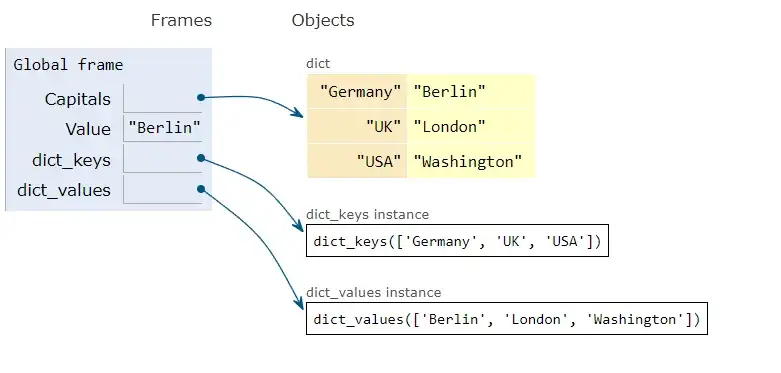
The dict instance methods .keys(), .values(), and .items() return instances of classes called dict_keys, dict_values, and dict_items that are read only but are dynamic proxies to the real dict, ie, If the source dict is updated, you can immediately see the changes through an existing view.
d = {'a': 5, 'b': 2, 'c': 0, 'd': 7}
v = d.values()
print('values before before updating : ', v)
# values before before updating : dict_values([5, 2, 0, 7])
d['e'] = 5
print('Dictionary after adding new value', d)
# Dictionary after adding new value {'a': 5, 'b': 2, 'c': 0, 'd': 7, 'e': 5}
# dynamic view object is updated automatically
print('value of the updated dictionary: ', v)
# value of the updated dictionary: dict_values([5, 2, 0, 7, 5])Practical Consequences of using Dictionaries
Python’s dict implementation is very efficient as it’s based on hash table but there are few things to keep in mind:
- Keys must be hashable objects. They must implement proper __hash__ and __eq__ methods.
- Item access by key is very fast. A dict may have millions of keys, but Python can locate a key directly by computing the hash code of the key and deriving an index offset into the hash table.
- To save memory, avoid creating instance attributes outside of the __init__ method.
- Dicts inevitably have a significant memory overhead.
Set Theory
A set is a collection of unique objects. A basic use case is removing duplication.
l = ['spam', 'spam', 'eggs', 'spam', 'bacon', 'eggs']
print(set(l))
# {'eggs', 'spam', 'bacon'}Set type and its immutable sibling frozenset are still underused in Python despite their usefulness, their elements must be hashable to enforce uniqueness.
In addition to this, Set type implements many infix operations.
# Defining the two sets
first_set = {1, 5, 7, 4, 5}
second_set = {4, 5, 6, 7, 8}
# Creating the intersection of the two sets
intersect_set = first_set & second_set
print(intersect_set) # Output: {4, 5}
# Creating the union of the two sets
union_set = first_set | second_set
print(union_set) # Output: {1, 2, 3, 4, 5, 6, 7, 8}
# Creating the difference of the two sets
diff_set = first_set - second_set
print(diff_set) # Output: {1, 2, 3}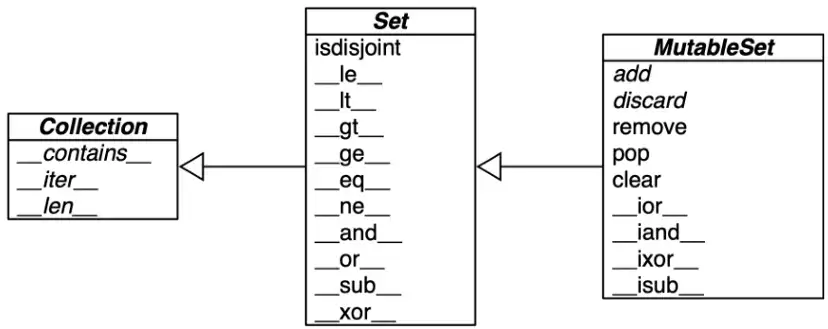
Set Comprehensions
SetComp is similar to listComp and dictComp, it’s the creation of a set based on existing iterables.
print({s for s in [1, 2, 1, 0]})
# set([0, 1, 2])Practical Consequences of Using Sets
- Set elements must be hashable objects. They must implement proper __hash__ and __eq__ methods.
- Membership testing is very efficient. A set may have millions of elements, but an element can be located directly by computing its hash code and deriving an index offset.
- Sets have a significant memory overhead, sometimes a low-level array would be more compact and efficient.
- Element ordering depends on insertion order, but not in a useful or reliable way
- Adding elements to a set may change the order of existing elements. That’s because the algorithm becomes less efficient if the hash table is more than two thirds full.
- Dict views implement similar operations to set operations, using set operators with views will save a lot of loops and ifs when inspecting the contents of dictionaries in your code.
Further reading
- The Python Standard Library documentation, “collections — Container datatypes”, includes examples and practical recipes with several mapping types
- The Third Chapter of the Book Fluent Python