Common Index Anomalies and Database Performance Tuning
Uncover prevalent query anomalies and discover practical approaches to fine-tune database performance


Navigating the complex world of database optimization poses a challenge, and thus far, we've explored how using indexes strategically significantly improves query performance.
In this piece, we delve into scenarios where indexes might be overlooked during the execution of queries and discuss strategies to prevent such occurrences. From the precision of partial indexes to the intricate relationships of multi-column indexes and the structured efficiency of clustering, we untangle the complexities that influence the database's decision to embrace or ignore these indexing strategies.
What causes an Index to be overlooked when executing a Query?
To understand why would an Index be overlooked when executing a query, we first have to understand Query Plans and their Cost Estimation.
What is a Query Plan?
A Query Plan, also known as an Execution Plan, is a detailed roadmap that a database management system (DBMS) generates to outline the steps it will take to execute a specific SQL query. The query plan provides insight into how the database engine will access and manipulate the data to fulfill the query.
Key components of a query plan include:
- Access Methods: Specifies how the database engine will access the data, such as using indexes, performing sequential scans, or utilizing specialized access methods.
- Join Methods: Describes how the database will perform joins between tables, indicating whether it will use nested loop joins, hash joins, or merge joins.
- Filtering and Sorting: Outlines any filters or conditions applied to the data and how the database will perform sorting, if required by the query.
- Aggregation and Grouping: Details how the database will handle aggregation functions and grouping operations specified in the query.
- Index Usage: Indicates whether and how indexes will be used to optimize data retrieval.
- Data Distribution and Parallelism: Provides information on how the database will distribute the workload across multiple processors or nodes in a parallel processing environment.
By examining the plan, we usually can identify potential bottlenecks, optimize indexing strategies, and make adjustments to improve overall query efficiency, this is done through tools and commands offered by Database management systems (e.g., EXPLAIN in PostgreSQL).
What interests us here is the Index Usage! This is where our database will decide whether or not we will be using an Index.
Why Would a Database Ignore an Index?
A database may ignore an index for several possible reasons:
- Statistical Inaccuracy: This refers to the situation where the statistical information about the data distribution, table sizes, and other relevant metrics is not reflective of the actual state of the database. If the statistics about the data distribution are inaccurate, the query planner may make suboptimal decisions, leading to the neglect of an index.
- Query Complexity: In some cases, the complexity of the query may lead the planner to opt for a sequential scan instead of using an index, especially if the indexed columns are not selectively filtered.
- Index Selectivity: This refers to the uniqueness and distribution of values within the indexed column(s) of a database table. It is a measure of how selective or specific an index is in terms of narrowing down the search space for a given query. The more selective an index is, the more efficiently it can filter and retrieve relevant rows. If the indexed column has low selectivity (i.e., a large portion of the data has the same or similar values), using the index may not be advantageous, and the planner might choose an alternative execution plan.
- Outdated Statistics: Outdated statistics on table distribution or column values can mislead the query planner. Regularly updating statistics is crucial for accurate decision-making.
- Complex Join Conditions: In queries involving multiple tables and complex join conditions, the planner might find it more efficient to use different join strategies, disregarding the indexed columns.
- Cost Estimation: The query planner estimates the cost of various execution plans, and if it perceives the cost of using the index as higher than other methods, it may opt for an alternative approach.
- Size of the Table: For small tables, a sequential scan may be more efficient than using an index. The planner considers the size of the table and the cost associated with index access.
- Functional Index Limitations: Certain types of queries or functions may not be compatible with certain types of indexes, leading the planner to ignore those indexes.
As seen above, the Query Planner will choose to ignore an Index if it deems the cost of using it is higher than other approaches. Similarly, the Index can be ignored if we have complicated join conditions, table statistics are out of date or the query can end up returning too many results which would indicate that traversing the whole table and ignoring the index may be the better way to go.
Understanding the specific context of the query, the structure of the database, and the characteristics of the data is essential to determine why a database might choose to ignore an index in a given scenario. Regularly updating statistics, analyzing query plans, and optimizing queries can help address and mitigate these issues, but most importantly we have to create good covering indexes!
What is a Covering Index and How to Create it?
A covering index or index with included columns, is an index that includes all the columns necessary to satisfy a specific query without the need to reference the actual data rows in the underlying table. This type of index is designed to "cover" a query, providing all the required information directly from the index structure, without requiring additional lookups in the main table.
there are multiple benefits to having a covering index such as:
- Improved Query Performance: Since the required data is available in the index itself, the database engine can fulfill the query requirements without having to access the actual data rows. This reduces the number of disk I/O operations and speeds up query execution.
- Reduced Disk I/O: Traditional indexes store a subset of columns and require additional disk I/O operations to fetch the remaining columns from the table. Covering indexes eliminate this need, leading to more efficient use of disk I/O.
- Minimized Memory Usage: The smaller size of covering indexes compared to the full table data can lead to better use of memory, as more index pages can be cached in memory.
- Optimized for Read-Heavy Workloads: Covering indexes are particularly useful in scenarios where there are frequent read operations and the goal is to optimize query performance.
- Reduced Lock Contention: In certain cases, covering indexes can reduce lock contention by allowing queries to retrieve the necessary information without locking the actual data rows in the table.
It's important to note that while covering indexes can significantly improve query performance, they also come with trade-offs. The indexes consume additional storage space, and there may be a slight overhead during write operations (inserts, updates, and deletes) as the indexes need to be maintained. The decision to create covering indexes should be based on the specific query patterns and performance requirements of the application.
How to Create a Covering Index Using Multi Column Index?
The first option to create a covering Index is to create a multi column index, so taking the previous analytics_event table we can, for example, create an index that covers the name and id columns.
CREATE INDEX CONCURRENTLY analytics_event_name_id_idx
ON analytics_event(name, id);If we try to query the database for the ids and names of the events we should get an Index only scan!
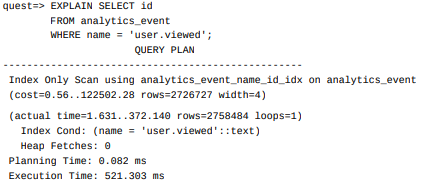
As shown in the example, once we added an index on (name, id) , we were able to get an Index Only Scan for the query SELECT id FROM analytics_event WHERE name = 'user.viewed' .
Sometimes multi column indexes can be an overkill. We've developed a data structure with the purpose of facilitating the retrieval of events based on both ID and name. However, what if our actual intention is not to perform searches by both criteria; rather, we aim for effortless access to the ID specifically when searching by name. Is there a more optimal solution?
How to Create a Covering Index Using the INCLUDE Parameter?
In the case of Postgres, starting from version 11, the CREATE INDEX command introduces a new parameter called INCLUDE. Let's create a covering index with the INCLUDE parameter and evaluate its query speed.
CREATE INDEX CONCURRENTLY analytics_event_name_idx
ON analytics_event(name)
INCLUDE (id)Now if we run EXPLAIN on our previous query:
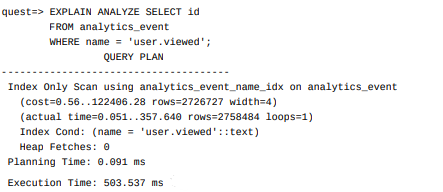
The INCLUDE version of the index is 21 milliseconds faster, so in this case, the difference is not huge but still, it’s an optimization worth exploring with different circumstances.
Please note that MySQL and SQLite lack a direct counterpart to the INCLUDE keyword found in Postgres. Nevertheless, both databases do support covering indexes by using multi-column indexes.
Partial Indexes
Another strategy to enhance indexing performance involves the creation of partial indexes for substantial tables. A partial index is characterized by a WHERE clause that selectively includes specific rows from the table in the index.
Partial indexes are more efficient and provide faster query performance for the subset of data that meets the specified conditions. This approach is particularly useful when dealing with large tables where only a fraction of the data needs to be indexed for certain queries.
In the following example, a partial index is created exclusively for "user.viewed" events, using the INCLUDE feature to encompass our query.
CREATE INDEX analytics_event_user_viewed_events
ON analytics_event (name)
INCLUDE (id)
WHERE name = 'user.viewed';Now for its query plan:
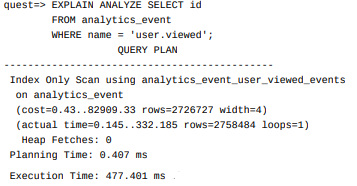
Look at that! we managed to optimize the execution time even more!
Now last but not least, we will check the last trick we can use that can save us from creating multiple partial indexes, as more indexes usually means worse write performance.
Clustering tables
Clustering refers to physically organizing related data in our physical storage to enhance performance. Instead of storing data in the order of insertion, clustering involves arranging rows on the disk based on the values of one or more columns. This organization can lead to improved query performance and reduced disk I/O operations.
In clustered tables, rows with similar or adjacent values in the clustering columns are stored together. This can be beneficial for certain types of queries, especially those that involve range queries or queries that access consecutive rows based on the clustering columns.
It's important to note that the concept of clustering is implemented differently in various database management systems (DBMS). In some databases, clustering is automatic based on the primary key, while in others, it might be a manual or configuration-driven process.
Key points about clustering tables in a database:
- Clustering Columns: The columns based on which the clustering is performed are known as clustering columns. These columns influence the physical order of data on disk.
- Query Performance: Clustering is often used to enhance the performance of specific types of queries, such as range queries or queries that involve the clustering columns.
- Storage Considerations: While clustering can improve certain aspects of query performance, it may impact insert and update operations. These operations might be slower due to the need to maintain the physical order of data.
- Database-Specific Implementation: The method of clustering and the options available can vary between different database systems. Some databases support automatic clustering, while others provide manual control over the clustering process.
- Indexing: Clustering can work in conjunction with indexes to further optimize query performance. Indexes on clustering columns can enhance the efficiency of data retrieval.
- Considerations for Maintenance: Regular maintenance tasks, such as reorganizing or rebuilding indexes, may be necessary to ensure optimal performance in a clustered environment.
It's essential to carefully consider the specific requirements and characteristics of the database system being used before deciding to cluster tables, as the impact on performance can vary based on factors such as workload and query patterns.
For example, if we have an index on the name field in an analytics_event table called analytics_event_name_idx , we could reorganize the table data by writing this:
CLUSTER analytics_event USING analytics_event_name_idx After clustering, a query for a value of name should be faster without us needing to create a partial index just for that value.
Conclusion
As seen today, a comprehensive understanding of query execution anomalies is crucial for effectively tuning database performance. This article has delved into various aspects, from recognizing common anomalies to implementing strategies for optimization.
By exploring the intricacies of query execution plans, indexing, and the impact of data distribution, we've gained insights into potential bottlenecks that can hinder performance. The importance of leveraging database management system tools and profiling techniques cannot be overstated in identifying and addressing these anomalies.
The discussion on query optimization strategies, including index selection, clustering, and the judicious use of covering indexes, emphasizes the proactive measures that database administrators and developers can take to enhance performance.
Ultimately, staying attuned to the dynamic nature of databases and the evolving demands of applications is essential. Regular monitoring, performance testing, and a proactive approach to addressing anomalies contribute to the creation of a robust and responsive database environment.