From B-trees to GIN: Navigating Django's Database Index Landscape
Dive into the world of Django database indexes, exploring the power of B-trees, GIN, GiST, and BRIN to optimize performance.


In this ever-evolving domain of ours, where prioritizing speed and efficiency is crucial, the effectiveness of your Django database is quite significant. As developers, we know that effective indexing is a cornerstone of optimizing database queries and enhancing overall system responsiveness.
In this article, we explore the diverse world of indexes in Django databases, specifically PostgreSQL. Beyond the previously seen B-trees, we'll explore an array of indexing options, from hash indexes to GIN indexes, unraveling their unique characteristics and use cases and equipping us with the knowledge to make informed decisions for our application's database performance, with GIN indexes being the base of a use case we will be working on.
Different Index Types
While B-tree indexes generally suit most use cases, the storage of unconventional and exotic data may warrant the consideration of alternative index types. Here are instances of alternative indexes and their applications:
- GIN indexes, designed for handling JSON data, particularly in PostgreSQL.
- GiST indexes, tailored for spatial data management within PostgreSQL.
- BRIN indexes, optimized for very large tables in PostgreSQL.
- Hash indexes, ideal for in-memory tables, commonly used in MySQL.
- R-tree indexes, which are similar to GiST Indexes but for MySQL, specialized for managing spatial data.
For those using PostgreSQL with Django, the framework conveniently provides BrinIndex, GinIndex, HashIndex and GistIndex classes, allowing for seamless application directly to models.
GIN Index
A GIN (Generalized Inverted Index) index is a type of index used in databases, particularly in PostgreSQL, to handle complex data types and accelerate search operations. Unlike traditional B-tree indexes, GIN indexes are well-suited for scenarios where the indexed data can have multiple values associated with a single row.
Here are the key points to retain:
- Generalized Inverted Index (GIN): GIN indexes are designed to handle various types of data structures efficiently.
- Array Data: GIN indexes excel when dealing with array data, allowing for quick searches based on the presence of specific values within an array.
- JSONB Data: In PostgreSQL, GIN indexes are often used for JSONB data types, enabling fast searches and queries on JSONB keys and values.
- Full-Text Search: GIN indexes can also be applied to full-text search data, providing rapid access to documents based on their textual content.
- Query Performance: GIN indexes are designed to enhance the performance of queries involving searching or filtering based on the elements within complex data structures.
To create a GIN index in PostgreSQL, we typically use the GIN keyword in the CREATE INDEX statement along with the specific column or expression.
CREATE INDEX gin_index_name ON table_name USING GIN(column_name);
GiST Index
GiST (Generalized Search Tree) indexes are a type of index used in databases, particularly in PostgreSQL, to optimize the retrieval of complex data types, especially spatial or geometric data. GiST indexes provide efficient support for searching, querying, and indexing multidimensional or specialized data structures.
Key points about GiST indexes:
- Generalized Search Tree (GiST): GiST is a flexible indexing structure that can accommodate various data types and query requirements.
- Spatial Data: GiST indexes are commonly used for spatial or geometric data, making them suitable for applications dealing with maps, locations, or any data with multidimensional characteristics.
- Efficient Querying: GiST indexes optimize queries involving geometric shapes, points, or ranges, allowing for fast retrieval of relevant data.
- Multidimensional Data Types: GiST is well-suited for indexing and searching multidimensional data, such as arrays, ranges, and geometric shapes.
- Custom Data Types: GiST indexes can be adapted for custom data types, making them versatile for different types of applications and scenarios.
- Django Integration: In Django, you can use the
GistIndexclass provided by thedjango.contrib.postgres.fieldsmodule to apply a GiST index to specific model fields, as shown in previous examples.
In PostgreSQL, we can create a GiST index using the CREATE INDEX statement with the USING GIST clause.
CREATE INDEX gist_index_name ON table_name USING GIST(column_name);
BRIN Index
A BRIN (Block Range Index) index is a type of index used in PostgreSQL databases to optimize the retrieval of large tables by storing and indexing ranges of data in blocks. BRIN indexes are particularly effective for scenarios where the data is naturally ordered, such as with timestamp or numeric data.
Here are key points about BRIN indexes:
- Block Range Index (BRIN): BRIN is designed for efficient indexing of large tables by dividing data into blocks and creating a summarized index.
- Naturally Ordered Data: BRIN indexes work well when the data is naturally ordered, such as with timestamp or numeric data. They take advantage of the inherent order to create a concise index.
- Block-Level Indexing: Instead of indexing every row individually, BRIN indexes focus on blocks of data, storing summary information about each block. This approach reduces the storage requirements for the index.
- Space Efficiency: BRIN indexes are space-efficient, making them suitable for large tables where traditional indexes may become unwieldy.
- Django Integration: In Django, you can use the
BrinIndexclass provided by thedjango.contrib.postgres.fieldsmodule to apply a BRIN index to specific model fields.
In PostgreSQL, you can create a BRIN index using the CREATE INDEX statement with the USING BRIN clause.
CREATE INDEX brin_index_name ON table_name USING BRIN(column_name);
Hash Index
A Hash index is a type of index used in databases to optimize the retrieval of data based on the hash value of indexed columns. Hash indexes are effective for equality queries where you need to quickly find a record with a specific value in the indexed column.
Here are key points about Hash indexes:
- Hash Function: Hash indexes use a hash function to map the values in the indexed column to fixed-size hash codes. These codes serve as pointers to the actual data storage location.
- Equality Queries: Hash indexes excel in scenarios where you need to perform equality queries, such as searching for a specific value in the indexed column.
- Quick Lookups: Hash indexes provide constant time (O(1)) lookups in ideal scenarios, making them efficient for certain types of queries.
- No Sorting: Unlike B-tree indexes, Hash indexes do not store values in a sorted order. This makes them less suitable for range queries or sorting operations.
- Collision Handling: Hash indexes may encounter collisions, where different values produce the same hash code. Techniques like chaining or open addressing are used to handle collisions and store multiple values with the same hash code.
- Django Integration: In Django, you can use the
HashIndexclass provided by thedjango.db.modelsmodule to apply a Hash index to specific model fields.
Creating a Hash index depends on the specific database system. In MySQL, for example, you can use the CREATE INDEX statement with the USING HASH clause.
CREATE INDEX hash_index_name ON table_name (column_name) USING HASH;
Use Case: Indexing JSON Data
The author of the book "The Temple of Django Database Performance" mentions two use cases where users might want to store data in JSON format:
- In the initial stages of a project, the aim is to swiftly create prototypes without establishing a formal schema. For example, instead of creating an Account model with distinct fields to store account data, we opt for an Account model featuring a single JSONField, encapsulating all data within that field. As the project evolves, we can choose whether to distribute that data into individual columns and relationships, essentially "normalizing" it or not.
- The data is currently structured with a formal schema, and we intend to denormalize certain parts of it (potentially duplicating and ensuring synchronization) to enhance overall performance. For instance, when constructing a web page displaying book details, involving data from multiple tables like publishers, authors, and editions, we might choose to denormalize by copying this data into a JSON metadata column within the books table. This approach facilitates swift retrieval of all metadata for a particular book, enhancing page rendering speed.
Now consider the Event Model we created in the previous article:
class Event(models.Model):
user = models.ForeignKey(
"auth.User", on_delete=models.CASCADE, related_name="events"
)
name = models.CharField(help_text="The name of the event", max_length=255)
data = JSONField()
class Meta:
indexes = [models.Index(fields=["name"])]
Consider a scenario where the event location is stored in the data column as latitude and longitude values. This implies that the data column includes a "latitude" key with a corresponding numerical value.
If we want to query our database to get an event in specific target latitude, we would write something like this:
from analytics.models import Event
TARGET_LAT = 44.523064
at_target_lat = Event.objects.filter(data__latitude=TARGET_LAT).count()
The Django ORM will generate and execute this SQL Query:
SELECT COUNT(*) AS "__count" FROM "analytics_event"
WHERE ("analytics_event"."data" -> 'latitude') = '44.523064'; Now if you check the previous article in this series, you will notice that we added a B-Tree Index on our Event model, or event table if you may, which is not currently being used!
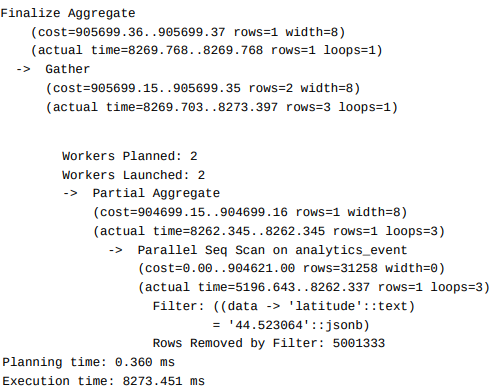
So we have two options:
- Adding a B-Tree index specifically on the "latitude" key, which will only be helpful if we're always making use of it knowing that it will only service the specified "latitude" key!
- Adding a GIN index which is not restricted to a single key, like "latitude" in our B-tree index but can service any key in the data JSON field!
Adding B-Tree Index on a Specific JSON Key
To do this, like before, we create the migration for it and run it concurrently so we can pass it smoothly in production!
class Migration(migrations.Migration):
atomic = False
dependencies = [
("analytics", "0001_initial"),
]
operations = [
migrations.RunSQL(
"CREATE INDEX CONCURRENTLY analytics_data_latitude_idx ON analytics_event((data -> 'latitude'));"
)
]
Now running the previous code and checking the query plan:
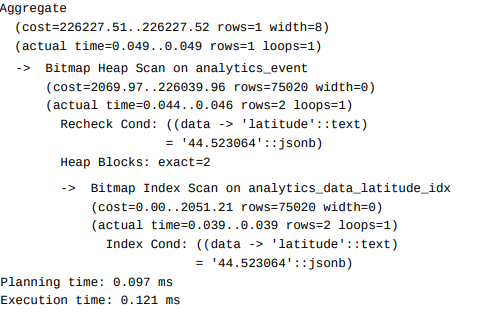
We can see the filter is using our index and the execution time is significantly improved, however, we still have the single key limitation, i.e. Indexing on "latitude" only, and if we change to filter the "longitude" we would still have the same execution time as before.
This is where GIN Index comes in as it is the type of index that is especially effective in handling "contains" logic for both JSON data and full-text search.
Adding a GIN Index
First let's change our code to use "__contains":
Event.objects.filter(data__contains={"latitude": 44.523064}).count()
Now the code generated by the ORM will be different as we are using a different directive!
SELECT COUNT(*) AS "__count"
FROM "analytics_event"
WHERE "analytics_event"."data" @> '{"latitude": 44.523064}';
Please note that the "@>" operator checks if a jsonb column contains the given JSON path or values.
Now we are ready to add our GIN Index since this falls under its capabilities, and this means modifying our previous Event Model which will allow us to index all top-level values with a single GIN index.
from django.contrib.postgres.fields import JSONField
from django.contrib.postgres.indexes import GinIndex
from django.db import models
class Event(models.Model):
user = models.ForeignKey(
"auth.User", on_delete=models.CASCADE, related_name="events"
)
name = models.CharField(help_text="The name of the event", max_length=255)
data = JSONField()
class Meta:
indexes = [
models.Index(fields=["name"]),
GinIndex(fields=["data"], name="analytics_data_gin_idx"),
]
Now, after adding the GIN index to cover the data column, any queries using the "__contains" operation on top-level keys within the data will use the index.
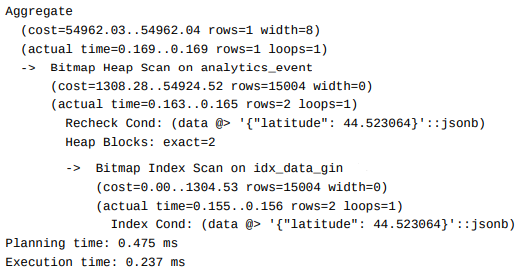
TL;DR
Using a GIN index along with "__contains" queries enables the retrieval of any top-level value in a JSONB column. Alternatively, a B-tree index on specific keys in a JSONB column is a reasonably fast option, though it is less flexible compared to the GIN index.
conclusion
Navigating the diverse landscape of Django's database indexes unveils a range of strategic options to optimize performance. From the versatile B-trees to specialized indexes like GIN, GiST, and BRIN, developers possess a toolkit to address various data scenarios.
The choice of index depends on the nature of the data, query patterns, and the project's evolving needs. Understanding the nuances of each index type empowers developers to make informed decisions, ensuring Django applications operate efficiently and responsively. As we navigate this dynamic terrain, the key lies in selecting and implementing indexes judiciously to strike the right balance between speed, flexibility, and resource efficiency.